1.16版本的PX4混控器改版了,Pipeline如下图:
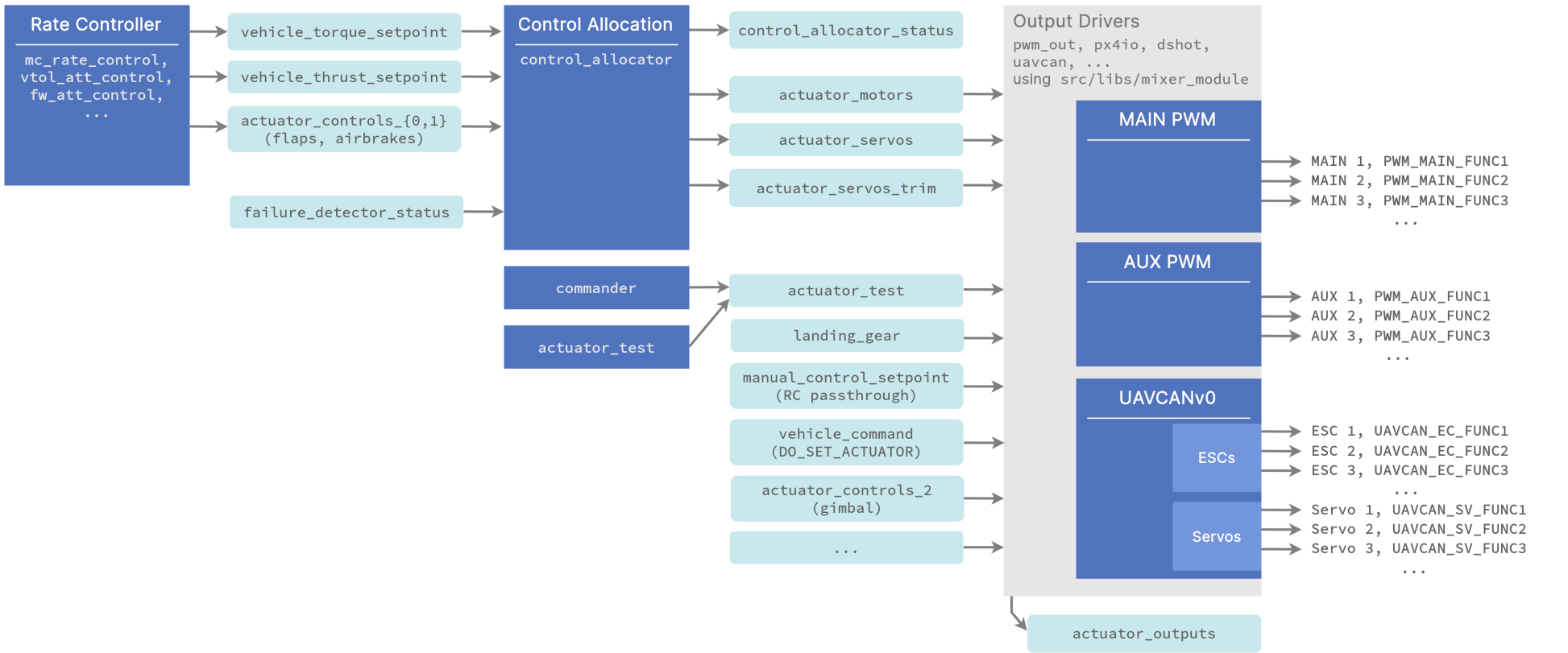 其中用于计算各执行器分配量的代码位于
其中用于计算各执行器分配量的代码位于src/lib/control_allocation/control_allocation。
控制分配器
控制分配器有两个版本,通过参数CA_METHOD控制。
伪逆法控制分配器
About 6 min
1.16版本的PX4混控器改版了,Pipeline如下图:
其中用于计算各执行器分配量的代码位于src/lib/control_allocation/control_allocation。
控制分配器有两个版本,通过参数CA_METHOD控制。
角度控制器主要代码位于src/modules/mc_att_control/AttitudeControl/AttitudeControl.cpp中,其核心为update函数。
角度控制采取了倾转分离的策略,倾斜(俯仰、偏航)的控制能力较强,而转向(偏航)的控制能力较弱,因此采用了不同的控制增益,将转向的控制量按比例缩小。
首先计算当前姿态和期望姿态分别对应的z轴方向(世界坐标系):
// calculate reduced desired attitude neglecting vehicle's yaw to prioritize roll and pitch
const Vector3f e_z = q.dcm_z();
const Vector3f e_z_d = qd.dcm_z();整体控制器结构如下
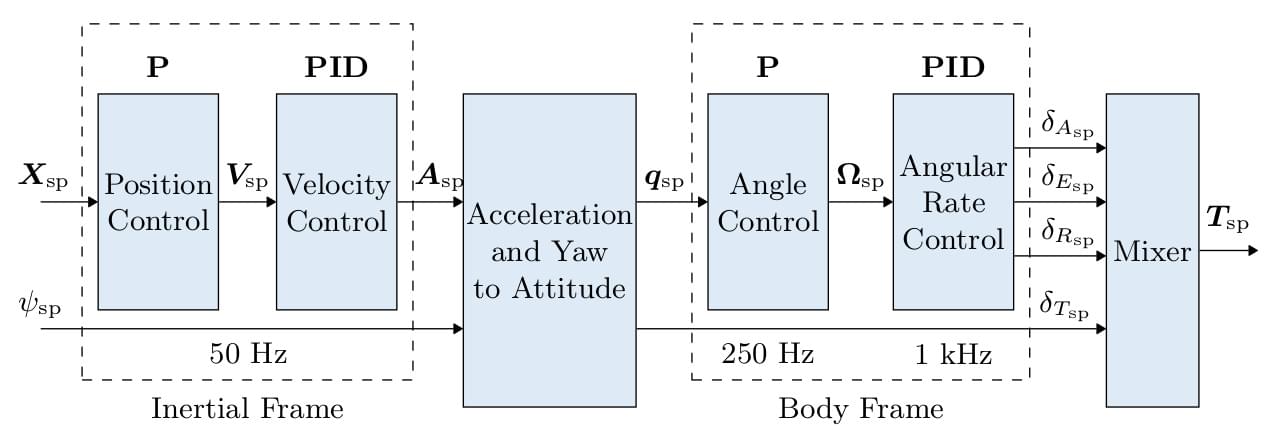
各模块分别位于:
src\modules\mc_pos_controlsrc\modules\mc_att_controlsrc\modules\mc_rate_controlsrc\modules\control_allocator如图所示,坐标系为旋转得到,记其三个单位基向量, , 在系下的坐标表示分别为, , ,则旋转矩阵为:
根据内积的定义,有
绕x, y, z三个轴旋转角的旋转矩阵为:
Info
下文的旋转矩阵、向量、四元数等都用右上标表明是在哪个坐标系下描述的。

Zhiyuan Liu, Leheng Li, Yuning Wang, Haotian Lin, Zhizhe Liu, Lei He, Jianqiang Wang 通讯作者:王建强,清华大学车辆与运载学院院长 arXiv: 2409.15135

本文是2021年关于MO RL和MO Planning的一篇综述。
MOMDP是一个六元组。其中,是状态空间,是动作空间,是状态转移函数,是折扣因子,是初始状态的概率分布,是vector-valued reward function,是目标数。
MOMDP下,agent执行策略,其Value function定义为
在这种情况下,价值函数是矢量,不像单目标RL那样,最优的定义并不是显而易见的。定义效用函数(utility function / scalarisation function),将价值函数映射到一个标量:
Shuo Feng, Henry X. Liu*, et. al. 22 March 2023 Nature Vol 615
ASP遵循“失败即否定(negation as failure, NAF)”原则,即尝试推导某个原子失败时,就否定该原子。
Aggregate就是一些在集合上执行的函数,集合通常是依照某些条件构建出来的。